javisantana.com
Cierre 2014
cerrando 2014
Faltan aún unos días para cerrar el año pero voy a adelantar el post para ver si lo cerramos un poco antes. No me extenderé demasiado este año.
En mi mesilla de noche tengo una foto que me hice el día que presenté mi proyecto fin de carrera con mis abuelos. Es lo último que veo nítido antes de quitarme las gafas de hipster que me compré hace unos meses.
La foto es bastante mala pero me hace recordar dos cosas: a mi abuela que se fue este año sin avisar y los valores que aprendí de ellos.
Este año he hecho el gilipollas a nivel que ni yo mismo me creo, he pasado las líneas que marcan esos valores con mucho, así que cuando me voy a la cama ese “hasta mañana” a la foto me ayudar a recordar donde están los esos límites que me enseñaron.
Traversing Quadtree
traversing webmercator quadtree with SQL
One of the things I’m doing lately is analyze datasets in order to improve rendering speed in CartoDB and see how postgres performs. Unfortunately (or not, who knows) I’m don’t know so much about geospatial indices so I try to analyze using a bunch of SQL queries with the help of explain analyze.
On our tiler we have a fixed number of mapnik workers that can run at the same time (obviously) and setting up a new worker to render an empty tile is too expensive or at least more than executing a SQL query to see if there is data in this tile.
I was thinking about how would be to generate a index to khow, given a SQL query, what are the empty tiles. One of the thinks that came to my mind was the recursive WITH postgres statement. At the end webmercator is based on a quadtree so we can iterate it using recursion. This is the query I wrote:
WITH RECURSIVE t(x, y, z, e) AS (
-- root node (0, 0, 0)
SELECT 0, 0, 0, exists(select 1 from ships where the_geom_webmercator && CDB_XYZ_Extent(0, 0, 0))
UNION ALL
-- coordinate for the children
SELECT x*2 + xx, y*2 + yy, z+1,
exists(select 1 from ships where the_geom_webmercator && CDB_XYZ_Extent(x*2 + xx, y*2 + yy, z+1)) from t,
-- iterate over 4 children
(VALUES (0, 0), (0, 1), (1, 1), (1, 0)) as c(xx, yy)
-- only for tiles with geometry and up to zoom level 8
where e AND z < 8
)
SELECT z, x, y FROM t where e
(CDB_XYZ_Extent method returns the bbox for the tile (x, y, z))
It takes 2.8 seconds on my laptop for a dataset distributed all over the world with ~800k points
This generates a table where you can lookup if a tile should be rendered.
Another similar approach is to analyze what tiles you should fetch in order to not retrieve too much information (lets say more than 4k points) but not query the database for tiles with a few points when you can use some parent tile to render (and use cache for that). The SQL query is similar, the only thing that changes is the count(*)
WITH RECURSIVE t(x, y, z, e) AS (
SELECT 0, 0, 0, (select count(*) from ships where the_geom_webmercator && CDB_XYZ_Extent(0, 0, 0))
UNION ALL
SELECT x*2 + xx, y*2 + yy, z+1, (select count(*) from ships where the_geom_webmercator && CDB_XYZ_Extent(x*2 + xx, y*2 + yy, z+1)) from t, (VALUES (0, 0), (0, 1), (1, 1), (1, 0)) as c(xx, yy) where e > 4000 AND z < 17
)
SELECT z, x, y, e FROM t where e > 0
notice in this case I raised the limit to 17, the recursion in the case stops before due the number of points, there are still 37 tiles with more than 4k points tho. It takes 9.8 seconds to generate for the same dataset. If we increase the number of points to 64k the time is reduced to a half.
I also created a map to see the quadtree in action:
El precio de una vida
Esta semana el gobierno español ha decidido traer a Miguel Pajares, un cura que estaba ayudando en África, contiagiado de ébola para ver si podían sacarlo del agujero.
El espectáculo ha sido lamentable pero esta vez no hablo del gobierno, he leído desde gente quejándose por el dinero hasta gente con miedo por si provocaba una epidemia de proporciones bíblicas.
Hace unos años, estando yo en cuarto de carrera, en una clase de economía, el profesor enunció un problema tal que así:
Cual es coste máximo admisible para la instalación de un semáforo en un cruce donde moría 1 persona al año.
Tuve la mala suerte de que me tocase a mi resolverlo en la pizarra y mi respuesta básicamente fue poco económica: “se pone sí o sí”. Lógicamente esa no era una respuesta válida en una clase de econonomía, así que me pasé unos minutos en la pizarra tratando de hacer cuentas que no me llevaban a ninguna parte.
Todo hasta que el profesor me dio una pista: la vida humana se valoraba en unos 10.000€, jústamente la equis que quedaba por despejar.
Dejando a un lado el problema, aquella situación me dejó marcado ¿Cómo alquien podría atreverse a poner precio a una vida humana? aunque fuese en una clase de economía en un desafortunado ejemplo.
En el tema del cura (que parece que era lo único importante aquí), que por desgracia ha muerto hoy, prefiero no tener opinión, prefiero no tener que sufrir la idea de ponerme en el pellejo del gestor o de la familia del hombre (*). Parece que otra gente no tiene tantos problemas en debatir alegremente cuando se habla de una vida.
(*) hace ya nos años que trato de no pensar mucho en el otro barrio
Encoding Point Map Animations
Encoding animated point map
During the latest World Cup you might have seen some animated maps with tweets around the world showing different colors depending the team people were talking about. Yes, the maps that look like a fireworks. Those maps are done using torque, a technology we developed at CartoDB. In this post I want to talk about how we encode the data that goes into the animation.
a little bit of history
Torque had a start a few years ago in a project where we needed to show the process of deforestation over time. If you imagine the standard web map, a bunch of tiles (generally PNG images) representing a portion of the earth, rendered on the server and put back in order on the client to show a seamless map. Static images are great, but don’t help much when you want to show changes over time. On top of showing change, we wanted to style the data dynamically and let our users control the playback.
At the time, the HTML5 canvas element was something new and not used by any major mapping library. We explored the concept of sending raw data to the client and rendering that data on the fly on canvas. What we found very early in the project was that rendering the data was easy (well, “easy”), generating and transfering the data was the hard part.
torque data format
Torque format is pretty simple. Each tile is an array of points and each point has two arrays, one for the time dimension and another for a variable, in our case intensity of deforestation at that point in time. Now in CartoDB, it takes a generic form where the value is set by the user.
[
{
x__uint8: 8, // webmercator snapped to tile pixel
y__uint8: 10,
date__uint16: [0, 10, 45, 46] // steps * floor( (date - min_date)/(max_date - min_date) )
vals__uint8: [1, 3, 5, 10], // values for steps aggregated
},
...
]So lets say that we are showing tweets for a day interval. In this example, at point 8, 10 for date 0 the number of tweets would be 1, for date 10 the tweets would be 3, and so on.
This format was proposed by Andrew Hill and there is a nice presentation about it. He got the idea from datacubes and the nice thing about it is that you can use the same XYZ tile system as static image tiles and you can generate the values for each tile with a single SQL API query.
The objective of this post is not explain in detail torque format (which is actually an on going task). Instead, I’d like to focus on how we encode the data in Torque tiles.
encoding torque tile
A core challenge to most web development is to show the user content as quickly as possible when they load the page. This is the same for making maps on the web. For Torque tiles, this means we needed to focus on both transfer size and how to encode the data as quickly and efficiently as possible.
The first step for us was to find clever ways to omit information that will not be visualized. Like TopoJSON the coordinates and dates are quantified, the values are aggreagated and all is encoded as integers. Integer arrays greatly improve the performance of compression for data transfer. Removing anything more puts us at risk of reducing visualization quality.
So next, we looked at how to arrange and encode data in each tile in order to improve the compression ration.
To understand our solution, let’s get 2 different datasets and we’ll try to re-arrange them for improvements. The first one is global tweets from a world cup match (1.3M points), the second one is a dataset of ship positions during the second world war (800k points). They are pretty different as we will see later.
The torque tile (0, 0, 0) size is:
tweets: 854kb, 197kb, 76% gzip compressed ratio
ships: 345kb, 60kb, 83% gzip compressed ratio
The compression ratio is pretty good (around 77%) but it can be improved
delta encoding
I’m a big fan of PNG encoding and the way it prepares the data (called the ‘filter step’ in the spec) to extract all the redundancy is pretty smart: simple, fast and very effective. In short, it computes the difference between adjacent pixels and then compresses the calculated values instead of the original data.
In the Torque format, dates are arranged in the array from earliest to latest and so always grow! These are perfect for Delta Encoding, and the compression ratio should obviously improve. Let’s see,
tweets: 854kb, 132kb, 84% (+8%)
ships: 345kb, 60kb, 83% (=)
In tweets we improve 8% but in ships dataset stay the same, why? let see an histogram of non-encodes dates values vs encoded values.
For tweets dataset:

For ships dataset:
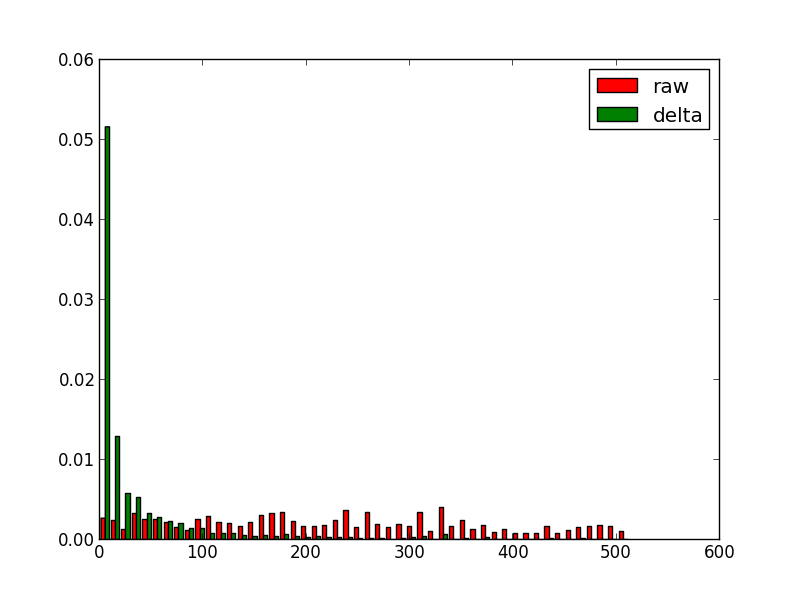
It’s clear that for tweets the date step is uniform so the delta works pretty well but for ships dataset altough there are symbols with higher frequency (around 0) there are still lot of them. Normally torque datasets are more like ships datasets in term of dates.
arrange things
The gzip compression algorithm works by looking for similar adjacent strings, so we can gain further improvements if we can arrange our data so like are near like. In our torque tile we could switch from an array of objects to a single object with different arrays,
{
x__uint8: [............],
y__uint8: [............],
vals__uint8: [............],
dates__uint16 : [............],
}the results for this are:
tweets: 854kb, 119kb, 86% (+10%)
ships: 345kb, 48kb, 86%, (+3%)
I tried some variations of this:
- sorting pixels in different order. No interesting change
- delta encoding pixels, dates and values (+1% ships datasets)
arrange data by step
what happens if we reorder the data in a totally different way. Instead of storing the data by coordinate, if the data is aggregated by time step, like:
{
0: {
x__uint8: [............],
y__uint8: [............],
vals__uint8: [............],
},
1: {...}
}the results:
tweets: 854kb, 329kb, 61% (-15%)
ships: 345kb, 50kb, 85%, (+3%)
Some surprises here, for first dataset the compression if far worse but for the second one it improves (but it’s not the best). So looks like depending on the data we can find different optimal arrangements.
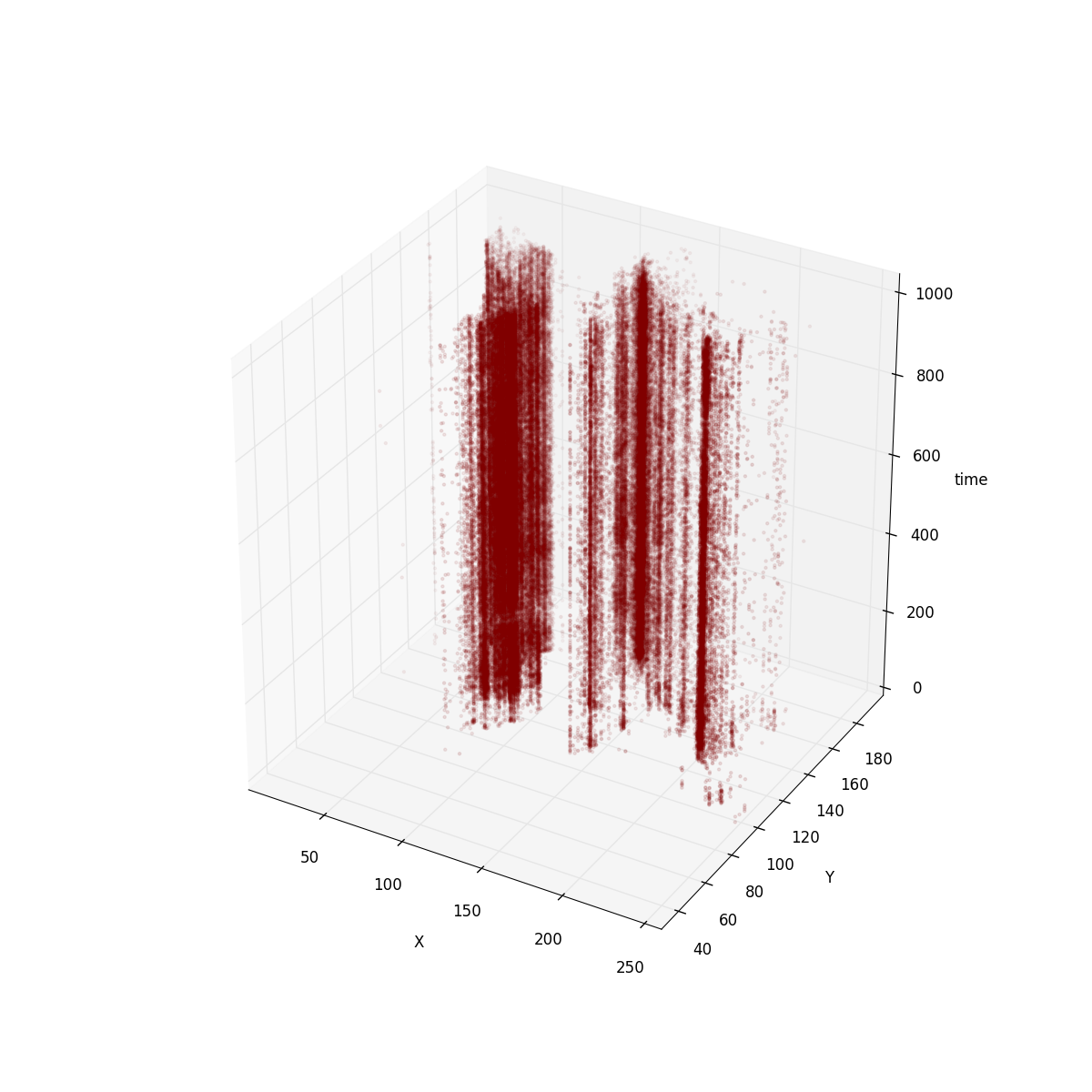
In order to understand this I plot the torque tile using a 3D graph.
For the tweets tile this is how it looks like:
for ships:
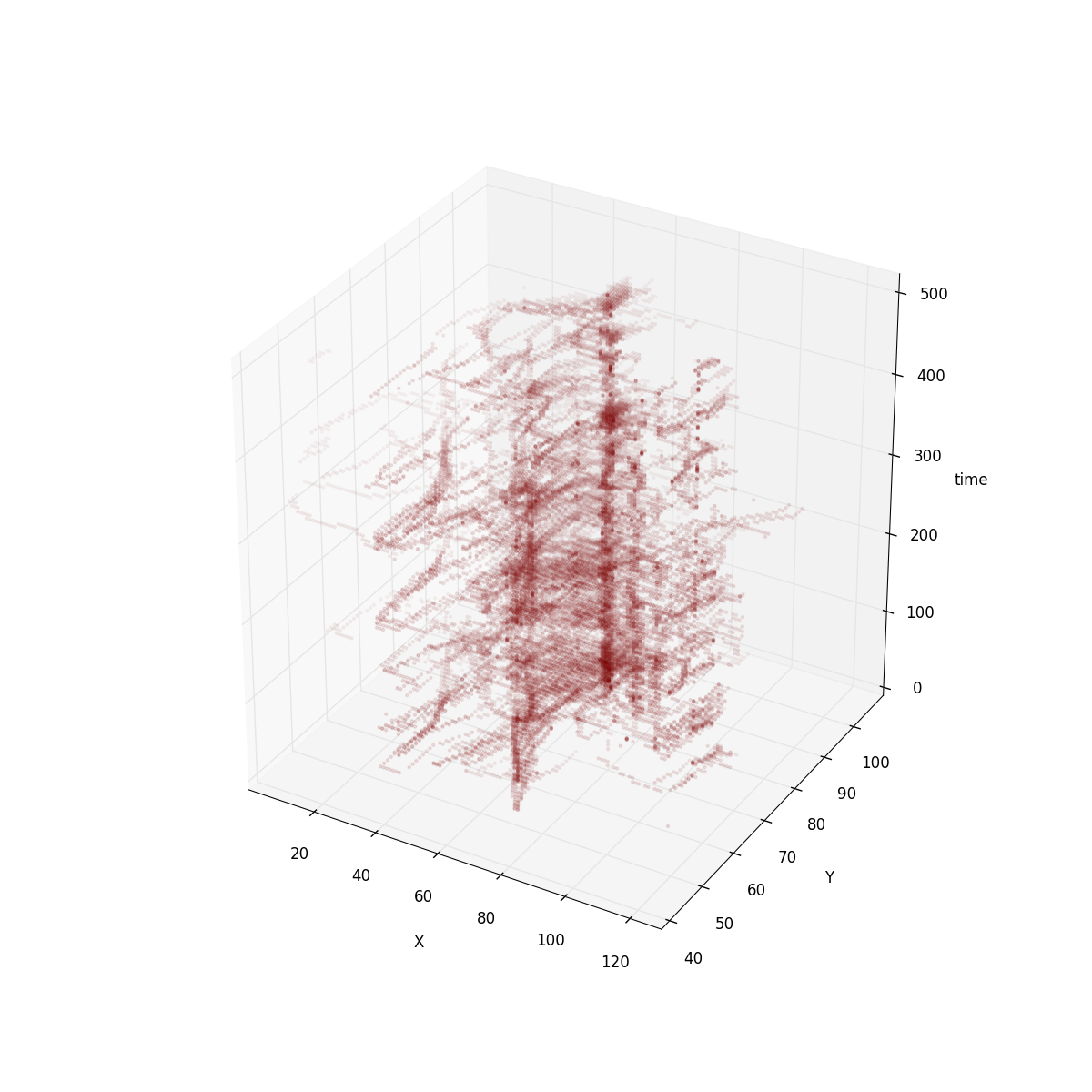
It’s clear that in tweets dataset the positions are more or less immutable. So encoding positions as keys is a good way to avoid duplicated data. For ships dataset the positions are not as fixed. However, if you imagine ships moving around the world, coordinates are follow an animated path, so delta encoding has a strong effect.
Although for the tweets dataset our compression ratio got worse with our last attempt it has other properties that make it appealing as our internal format.
-
This is the format the renderer uses internally for rendering so less time will be spent decoding and less intermediate memory used
Like I said, I’m a big fan of PNG approach. Some of the existing filtering techniques could still be applied to the Torque format. Especially if Torque is storing animated raster datasets filters like paeth could work between time slots. Take a look to the 3D view of this “animated raster dataset”:
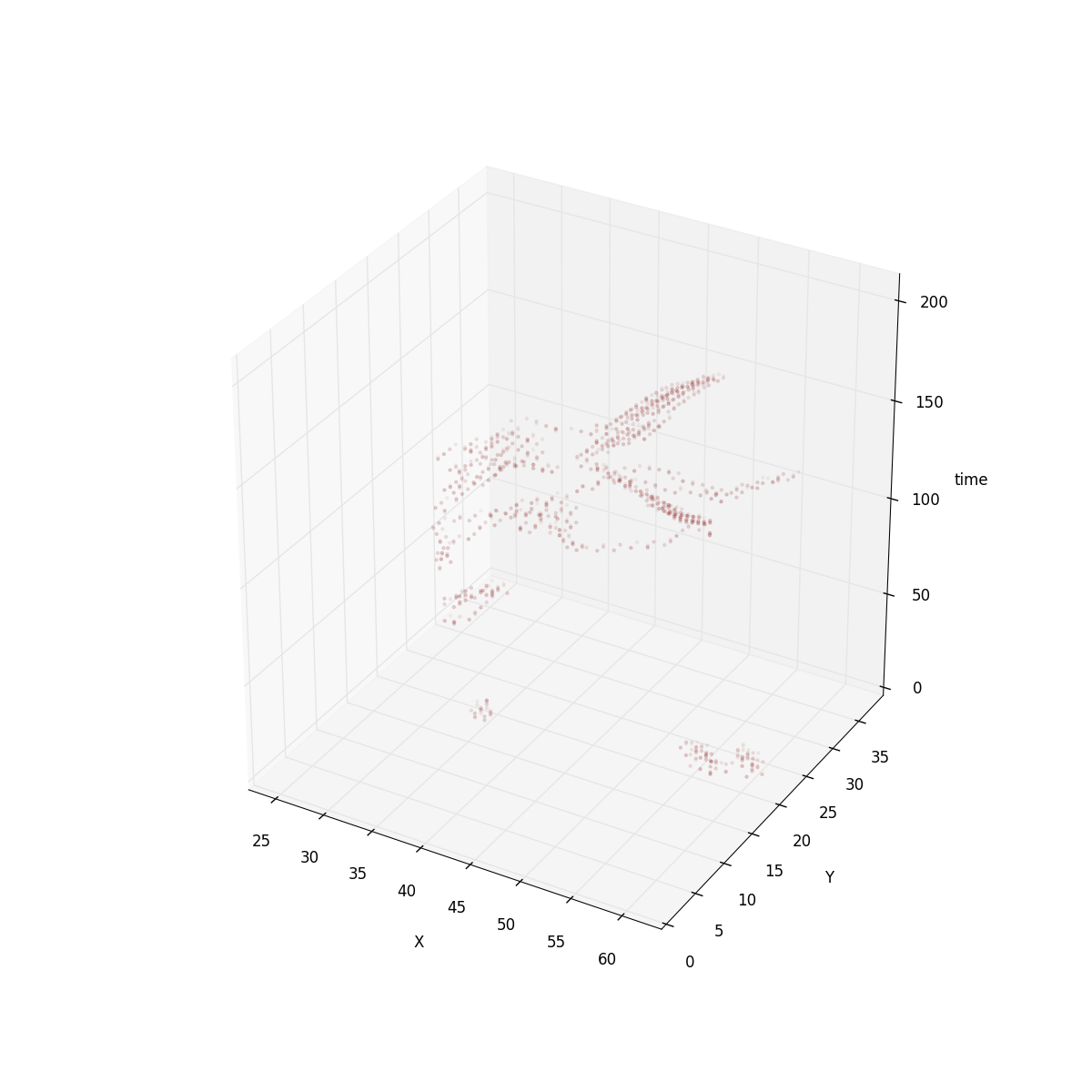
- Finaly, the PNG interlacing approach makes sense here. The way it works is using subdivision and could be used exactly in the same way for quadtree tiles.
try torque.js. You can find the data and the source code for the analysis in my github account
Lanzamos Agroguia Tracker
Lanzamos agroguía tracker
Esta semana hemos lanzado Agroguía tracker, una aplicación para móviles que permite al agricultor llevar toda la gestión de los trabajos que realiza en sus parcelas con GPS. Si no lo conoces, Agroguía (a secas) es una herramienta que gracias al GPS ayuda al guiado durante las labores que realizan los agricultores. Es una herramienta que desarrollamos y vendemos hace ya 8 años.
Este post no es más que un pequeño resumen del cómo y el porqué (y de paso hacer un poco de SEO).
Hace unos 6 años aproximadamente una mañana de sábado se me ocurrió que sería buena idea que los agricultores pudiesen revisar su trabajo una vez llegasen a casa. La idea evolucionó cuando vi a algunos agricultores usar esa capacidad de Agroguía para llevar la cuenta de dónde habían ido y qué había hecho. Algo tan simple como eso se puede convertir en un infierno si tienes más de 50 parcelas como tienen algunos de nuestros clientes.
La última versión más o menos grande de Agroguía fue hace 2 años, en ella decidimos incluir una funcionalidad que, igual que strava o runkeeper, envía un informe del trabajo realizado por el agricultor a su correo para analizaro, llevar la cuenta o símplemente ver alguna nota. A día de hoy tenemos miles de trabajos y muchos agricultores que han abandonado ya el cuaderno y lápiz que llevaban en el tractor. Aquí uno de los trabajos donde se trata solo la parte que riega el pivot:
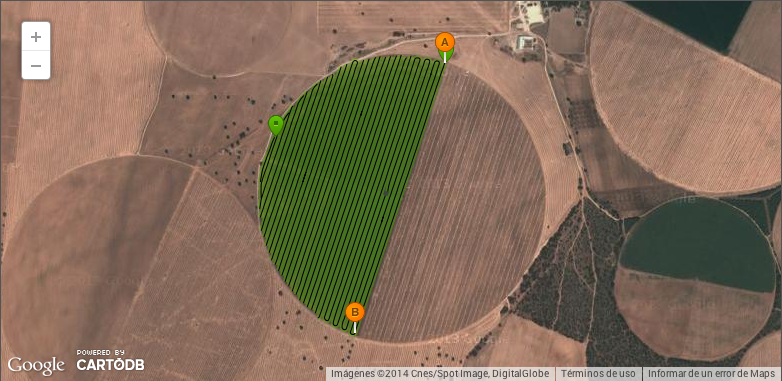
o este otro donde se ve como trabaja un avión. He dicho que tenemos una versión especial de guiado GPS para aviones y helicópteros?

Durante este tiempo hemos recibido muchas llamadas interesadas exclusivamente en esa funcionalidad (que dicho de paso es totalmente secundaria) así que pensamos que sería una buena idea sacar un subproducto de forma que pudiesemos vender eso por separado. Otra de las razones para hacer esto es intentar llegar a zonas donde antes no llegabamos, por ejemplo cosechadoras y empacadoras, que precisamente funcionan durante los periodos donde la venta de Agroguía baja mucho. En realidad hay otras cuantas razones más, pero esas mejor las cuento en persona.
El desarrollo ha sido bastante intermitente, de hecho la idea era lanzarlo a principios de mayo para hacer la campaña de mailing y demás antes de que empezase la cosecha, pero hemos llegado un pelín tarde y la aplicación tiene todo lo que me hubiese gustado, pero siempre es mejor ir haciendo basándose en lo que te van diciendo que sacar la bola de cristal como bien dicen en “Getting real” (el libro de cuando los de 37signals no estaban podridos de pasta y que de verdad es un must read). La aplicación no tiene ni nombre, pero tampoco importa ahora demasiado, no hemos venido aquí a lucir palmito, estamos tratando de resolver un problema real y ganar dinero (y hacerlo ganar) con ello. Probablemente ver como alguien resuelve un problema del mundo real con algo que tú has desarrollado es de las cosas que más llenan como programador.
Lo siguiente será ver como la gente reacciona, hemos tratado de enforcarlo como una herramienta de GPS para cosechadoras, pero en realidad es una herramienta que permite construir aplicaciones orientadas a casi cualquier cosa del ámbito agrícola, así que posiblemente vayamos usándola a lo largo del año para otros menesteres. Es algo bastante nuevo, así que seguramente habrá mucho trabajo de explicar qué es y cómo funciona, lo mismo que hicimos hace 8 años con el guiado GPS.
Como curiosidad, la tecnología que hace que todo esto funcione va a hacer 9 años, para que luego digan que hacer un buen diseño técnico no merece la pena.